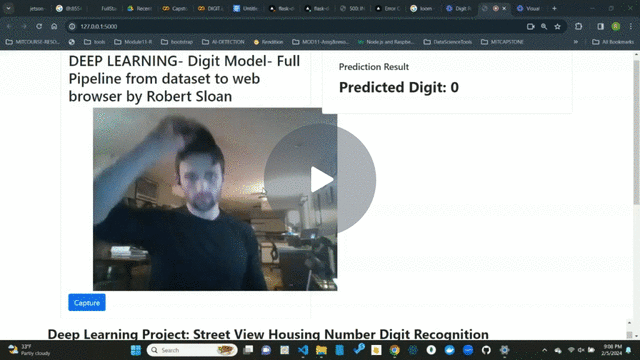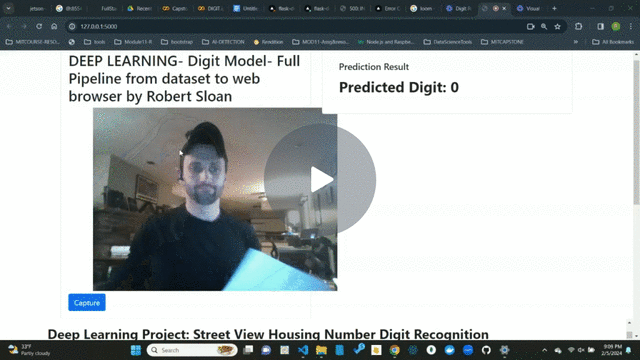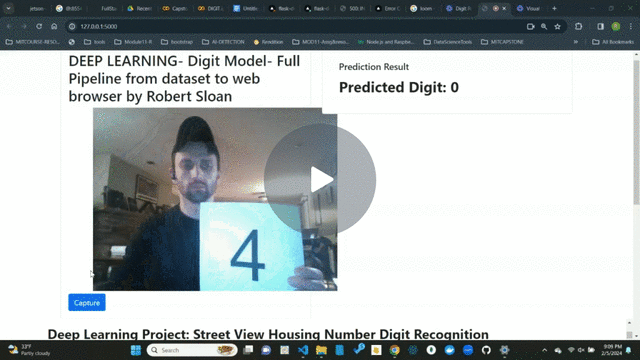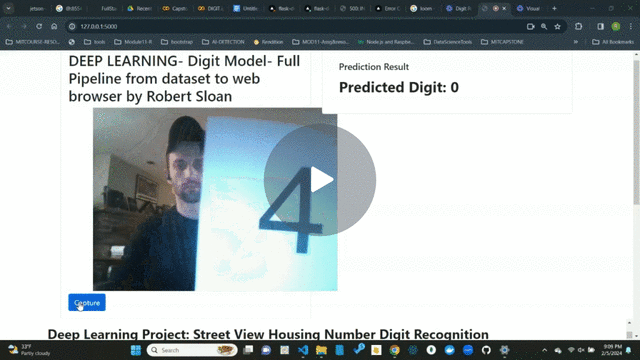
One of the most interesting tasks in deep learning is to recognize objects in natural scenes. The ability to process visual information using machine learning algorithms can be very useful as demonstrated in various applications.
The SVHN dataset contains over 600,000 labeled digits cropped from street-level photos. It is one of the most popular image recognition datasets. It has been used in neural networks created by Google to improve the map quality by automatically transcribing the address numbers from a patch of pixels. The transcribed number with a known street address helps pinpoint the location of the building it represents.
Our objective is to predict the number depicted inside the image by using Artificial or Fully Connected Feed Forward Neural Networks and Convolutional Neural Networks. We will go through various models of each and finally select the one that is giving us the best performance.
Here, we will use a subset of the original data to save some computation time. The dataset is provided as a .h5 file. The basic preprocessing steps have been applied on the dataset.
Let us start by mounting the Google drive. You can run the below cell to mount the Google drive.
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
# Importing the needed librarys that we need.
import numpy as np #importing numpy
import pandas as pd #importing pandas for handling data frames
import matplotlib.pyplot as plt #importing matplotlib for plotting
import seaborn as sns #importing seaborn for plotting
import cv2 #importing cv2 for image processing
from sklearn.model_selection import train_test_split #importing train_test_split for splitting the data
from sklearn.preprocessing import MinMaxScaler # importing MinMaxScaler for adjusting numerical values to between -0 and 1
import tensorflow as tf # importing tensorflow for building neural netowkrs
from tensorflow.keras.models import Sequential #importing Sequential for building neural networks
from tensorflow.keras.layers import Dense, Dropout, Activation, BatchNormalization, Flatten, Conv2D, MaxPooling2D, LeakyReLU, BatchNormalization, Activation, LeakyReLU #importing layers for building neural networks
from tensorflow.keras.losses import categorical_crossentropy #importing categorical_crossentropy for calculating loss
from tensorflow.keras.optimizers import Adam #importing Adam for optimizing the model
from tensorflow.keras.utils import to_categorical #importing to_categorical for one-hot encoding
Let us check the version of tensorflow.
# Check that we have loaded the correct version of tensorflow
print(tf.__version__)
2.12.0
import h5py #importing h5py for loading the dataset
# Load the data
with h5py.File('/content/drive/My Drive/ElectiveProjects/svhn.h5', 'r') as hf:
X_train = hf['X_train'][:]
y_train = hf['y_train'][:]
X_test = hf['X_test'][:]
y_test = hf['y_test'][:]
hf.close()
Check the number of images in the training and the testing dataset.
len(X_train), len(X_test) # Checking the number of images in training and testing data
print('The Training Set has', '{}'.format(len(X_train)), 'images')
print('The Testing Set has', '{}'.format(len(X_test)), 'images')
The Training Set has 42000 images The Testing Set has 18000 images
# Checking the Shape of the X_train and X_shape Data
X_train.shape
print('The Shape of the training set is:', {X_train.shape})
print('The Shape of the testing set is:', {X_test.shape})
The Shape of the training set is: {(42000, 32, 32)}
The Shape of the testing set is: {(18000, 32, 32)}
# Checking the shape of the y_train and y_test data
y_train.shape
print('The Shape of the training set is:', {y_train.shape})
print('The Shape of the testing set is:', {y_test.shape})
The Shape of the training set is: {(42000,)}
The Shape of the testing set is: {(18000,)}
X_train[0] # Checking the first image in the training data
array([[ 33.0704, 30.2601, 26.852 , ..., 71.4471, 58.2204, 42.9939],
[ 25.2283, 25.5533, 29.9765, ..., 113.0209, 103.3639, 84.2949],
[ 26.2775, 22.6137, 40.4763, ..., 113.3028, 121.775 , 115.4228],
...,
[ 28.5502, 36.212 , 45.0801, ..., 24.1359, 25.0927, 26.0603],
[ 38.4352, 26.4733, 23.2717, ..., 28.1094, 29.4683, 30.0661],
[ 50.2984, 26.0773, 24.0389, ..., 49.6682, 50.853 , 53.0377]],
dtype=float32)
Observation:
# Plotting the first 10 images in the training set and their labels
plt.figure(figsize=(10, 1))
for i in range(10):
plt.subplot(1, 10, i+1)
plt.tight_layout()
plt.imshow(X_train[i], cmap='gray', interpolation='none')
plt.title("Digit: {}".format(y_train[i]))
plt.xticks([])
plt.yticks([])
plt.show()

# checking the data set for how many unique items are stored in the 10 categorical options.
unique, counts = np.unique(y_train, return_counts=True)
print(np.asarray((unique, counts)).T)
[[ 0 4186] [ 1 4172] [ 2 4197] [ 3 4281] [ 4 4188] [ 5 4232] [ 6 4168] [ 7 4192] [ 8 4188] [ 9 4196]]
sns.distplot((y_train)) # checking the distribution of the data
plt.figure(figsize = (20, 20))
plt.show()
<ipython-input-35-a20a5f2b62b4>:1: UserWarning: `distplot` is a deprecated function and will be removed in seaborn v0.14.0. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms). For a guide to updating your code to use the new functions, please see https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751 sns.distplot((y_train)) # checking the distribution of the data

<Figure size 2000x2000 with 0 Axes>
Observations: All ten categorical labels have roughly the same amount of labeled images. The categorys of 5 and three have the most, only by a small amount though. The Data set seems to be evenly distributed.
# Shape and the array of pixels for the first image
print("Shape:", X_train[0].shape)
print()
print("First image:\n", X_train[0])
Shape: (32, 32) First image: [[ 33.0704 30.2601 26.852 ... 71.4471 58.2204 42.9939] [ 25.2283 25.5533 29.9765 ... 113.0209 103.3639 84.2949] [ 26.2775 22.6137 40.4763 ... 113.3028 121.775 115.4228] ... [ 28.5502 36.212 45.0801 ... 24.1359 25.0927 26.0603] [ 38.4352 26.4733 23.2717 ... 28.1094 29.4683 30.0661] [ 50.2984 26.0773 24.0389 ... 49.6682 50.853 53.0377]]
print(X_train[1]) # Checking the second image
[[86.9591 87.0685 88.3735 ... 91.8014 89.7477 92.5302] [86.688 86.9114 87.4337 ... 90.7306 87.204 88.5629] [85.9654 85.8145 85.9239 ... 63.8626 59.8199 54.8805] ... [90.2236 91.0448 93.4637 ... 55.3535 48.5822 44.0557] [90.6427 90.4039 90.937 ... 78.2696 77.4977 74.27 ] [88.0236 88.1977 86.6709 ... 75.2206 76.6396 79.2865]]
# Train Test Splitting of the Data
X_train = X_train.reshape(X_train.shape[0], 1024)
X_test = X_test.reshape(X_test.shape[0], 1024)
# Checking the Xtraining shape
X_train.shape
(42000, 1024)
# Normalize inputs from 0-255 to 0-1
X_train = X_train / 255.0 # Dividing the training data by 255 to normalize it.
X_test = X_test / 255.0 # Dividing the testing data by 255 to normalize
Print the shapes of Training and Test data
# New shape
print('Training set:', X_train.shape, y_train.shape) # Printing the shape of the training and testing data.
print('Test set:', X_test.shape, y_test.shape) # Printing the shape of the training and testing data.
Training set: (42000, 1024) (42000,) Test set: (18000, 1024) (18000,)
# One-hot encode output
y_train = to_categorical(y_train) # Converting the labels to categorical data
y_test = to_categorical(y_test) # Converting the labels to categorical data
# Test labels
y_test # Printing the labels2
print('The shape of the labels is:', {y_test.shape})
array([[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 1., ..., 0., 0., 0.]], dtype=float32)
Observation:
# Fixing the random seed generator to ensure random initilization numbers
np.random.seed(42) # Setting the seed to 42
import random # Importing the random library
random.seed(42) # Setting the seed to 42
tf.random.set_seed(42) # Setting the seed to 42
# ANN Model
def nn_model_1():
# Initialize a Sequential Model
model = Sequential()
# The first hidden layer, 64 neurons, rectified linear activation function, with input shape if (1024,)
model.add(Dense(64, activation='relu', input_shape=(1024,))) # the first dense layer has an input shape
#Second hidden layer that has 32 neurons and again the activation function is rectified linear.
model.add(Dense(32, activation='relu'))
# The output layer has 10 neurons that corrospond to the 10 categorical options for classification. Soft max activaction function for the output.
model.add(Dense(10, activation='softmax'))
# Compiling the model, with an Adam optimizer, the learning rate , and categorical_crossentropy as our loss method
model.compile(optimizer=Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
return model
# Build the model
model_1 = nn_model_1()
# Model Summary for nn_model_ Sequential neural network
model_1.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 64) 65600
dense_3 (Dense) (None, 32) 2080
dense_4 (Dense) (None, 10) 330
=================================================================
Total params: 68,010
Trainable params: 68,010
Non-trainable params: 0
_________________________________________________________________
# Training the model for 20 epochs with a batch size of 128 and a test train split of .2
history_model_1 = model_1.fit(X_train, y_train, validation_split=0.2, batch_size=128, verbose=1, epochs=20) #
Epoch 1/20 263/263 [==============================] - 4s 11ms/step - loss: 2.2934 - accuracy: 0.1233 - val_loss: 2.2324 - val_accuracy: 0.1744 Epoch 2/20 263/263 [==============================] - 2s 8ms/step - loss: 2.0774 - accuracy: 0.2509 - val_loss: 1.9318 - val_accuracy: 0.3089 Epoch 3/20 263/263 [==============================] - 2s 6ms/step - loss: 1.8679 - accuracy: 0.3405 - val_loss: 1.7779 - val_accuracy: 0.3869 Epoch 4/20 263/263 [==============================] - 1s 5ms/step - loss: 1.6573 - accuracy: 0.4391 - val_loss: 1.5288 - val_accuracy: 0.4907 Epoch 5/20 263/263 [==============================] - 1s 5ms/step - loss: 1.4635 - accuracy: 0.5180 - val_loss: 1.4202 - val_accuracy: 0.5255 Epoch 6/20 263/263 [==============================] - 2s 6ms/step - loss: 1.3588 - accuracy: 0.5568 - val_loss: 1.3240 - val_accuracy: 0.5768 Epoch 7/20 263/263 [==============================] - 2s 6ms/step - loss: 1.2895 - accuracy: 0.5839 - val_loss: 1.2558 - val_accuracy: 0.6013 Epoch 8/20 263/263 [==============================] - 2s 6ms/step - loss: 1.2375 - accuracy: 0.6044 - val_loss: 1.2217 - val_accuracy: 0.6221 Epoch 9/20 263/263 [==============================] - 4s 14ms/step - loss: 1.1990 - accuracy: 0.6206 - val_loss: 1.1674 - val_accuracy: 0.6330 Epoch 10/20 263/263 [==============================] - 3s 11ms/step - loss: 1.1666 - accuracy: 0.6334 - val_loss: 1.1484 - val_accuracy: 0.6420 Epoch 11/20 263/263 [==============================] - 2s 7ms/step - loss: 1.1465 - accuracy: 0.6399 - val_loss: 1.1256 - val_accuracy: 0.6462 Epoch 12/20 263/263 [==============================] - 3s 12ms/step - loss: 1.1239 - accuracy: 0.6485 - val_loss: 1.1110 - val_accuracy: 0.6533 Epoch 13/20 263/263 [==============================] - 4s 17ms/step - loss: 1.1017 - accuracy: 0.6589 - val_loss: 1.0951 - val_accuracy: 0.6612 Epoch 14/20 263/263 [==============================] - 4s 15ms/step - loss: 1.0981 - accuracy: 0.6596 - val_loss: 1.0940 - val_accuracy: 0.6620 Epoch 15/20 263/263 [==============================] - 2s 8ms/step - loss: 1.0854 - accuracy: 0.6636 - val_loss: 1.0948 - val_accuracy: 0.6650 Epoch 16/20 263/263 [==============================] - 3s 10ms/step - loss: 1.0715 - accuracy: 0.6682 - val_loss: 1.1295 - val_accuracy: 0.6475 Epoch 17/20 263/263 [==============================] - 3s 10ms/step - loss: 1.0626 - accuracy: 0.6713 - val_loss: 1.0618 - val_accuracy: 0.6744 Epoch 18/20 263/263 [==============================] - 2s 7ms/step - loss: 1.0535 - accuracy: 0.6746 - val_loss: 1.0626 - val_accuracy: 0.6702 Epoch 19/20 263/263 [==============================] - 3s 12ms/step - loss: 1.0486 - accuracy: 0.6745 - val_loss: 1.0610 - val_accuracy: 0.6736 Epoch 20/20 263/263 [==============================] - 3s 12ms/step - loss: 1.0420 - accuracy: 0.6770 - val_loss: 1.0535 - val_accuracy: 0.6745
# Epoch Accuracy and Validation Accuracy for ANN model_1
dict_hist = history_model_1.history # Defining a sotred model in history
list_ep = [ i for i in range(1, 21)]
plt.figure(figsize = (10, 10))# plotting the figure
plt.plot(list_ep, dict_hist['accuracy'], ls = '--', label = 'accuracy')
plt.plot(list_ep, dict_hist['val_accuracy'], ls = '--', label = 'val_accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
Text(0, 0.5, 'Accuracy')

%load_ext tensorboard
%tensorboard --logdir lightning_logs/
The tensorboard extension is already loaded. To reload it, use: %reload_ext tensorboard
Reusing TensorBoard on port 6006 (pid 86969), started 1:51:33 ago. (Use '!kill 86969' to kill it.)
import matplotlib.pyplot as plt
# Create a figure with two subplots.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# Plot the validation loss for each epoch.
ax1.plot(history_model_1.history['val_loss'], label='Validation Loss')
ax1.set_title('Validation Loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.legend()
# Plot the validation accuracy for each epoch.
ax2.plot(history_model_1.history['val_accuracy'], label='Validation Accuracy')
ax2.set_title('Validation Accuracy')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
ax2.legend()
# Show the plot.
plt.show()

# Create a figure with two subplots.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# Plot the validation loss for each epoch.
ax1.plot(history_model_1.history['val_loss'], label='Validation Loss')
ax1.set_title('Validation Loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.legend()
# Plot the validation accuracy for each epoch.
ax2.plot(history_model_1.history['val_accuracy'], label='Validation Accuracy')
ax2.set_title('Validation Accuracy')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
ax2.legend()
# Show the plot.
plt.show()
# Get the loss and accuracy values for each epoch.
loss = history_model_1.history['loss']
val_loss = history_model_1.history['val_loss']
acc = history_model_1.history['accuracy']
val_acc = history_model_1.history['val_accuracy']
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
ax1.hist(loss, bins=20, label='Loss')
ax1.hist(val_loss, bins=20, label='Validation Loss')
ax1.set_title('Loss')
ax1.set_xlabel('Loss')
ax1.set_ylabel('Frequency')
ax1.legend()
ax2.hist(acc, bins=20, label='Accuracy')
ax2.hist(val_acc, bins=20, label='Validation Accuracy')
ax2.set_title('Accuracy')
ax2.set_xlabel('Accuracy')
ax2.set_ylabel('Frequency')
ax2.legend()
plt.show()

**Observations: The first Artifical Neural Network built (nn_model_1) which constisted of 3 Dense layers, 68,010 trainable parameters, Two relu activiation functions and a softmax for the output layer. The model did not perform well with a final accuracy of 67%.
Let's build one more model with higher complexity and see if we can improve the performance of the model.
First, we need to clear the previous model's history from the Keras backend. Also, let's fix the seed again after clearing the backend.
# Fixing random seed generator before every new model
np.random.seed(42)
import random
random.seed(42)
tf.random.set_seed(42)
# New ANN Model 2
def nn_model2():
model = Sequential()
model.add(Dense(256, activation='relu', input_shape=(1024,)))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(BatchNormalization())
model.add(Dense(10, activation='softmax'))
model.compile(optimizer=Adam(learning_rate=0.0005), loss='categorical_crossentropy', metrics=['accuracy'])
return model
# Build the model
model_2 = nn_model2()
# Print the summary of the model
model_2.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_5 (Dense) (None, 256) 262400
dense_6 (Dense) (None, 128) 32896
dropout_1 (Dropout) (None, 128) 0
dense_7 (Dense) (None, 64) 8256
dense_8 (Dense) (None, 64) 4160
dense_9 (Dense) (None, 32) 2080
batch_normalization_2 (Batc (None, 32) 128
hNormalization)
dense_10 (Dense) (None, 10) 330
=================================================================
Total params: 310,250
Trainable params: 310,186
Non-trainable params: 64
_________________________________________________________________
# Fit the model
history = model_2.fit(X_train, y_train, validation_split=0.2, batch_size=128, verbose=1, epochs=30)
Epoch 1/30 263/263 [==============================] - 9s 26ms/step - loss: 2.3301 - accuracy: 0.1020 - val_loss: 2.3126 - val_accuracy: 0.0969 Epoch 2/30 263/263 [==============================] - 5s 18ms/step - loss: 2.3040 - accuracy: 0.1043 - val_loss: 2.3018 - val_accuracy: 0.1049 Epoch 3/30 263/263 [==============================] - 4s 14ms/step - loss: 2.1035 - accuracy: 0.2029 - val_loss: 1.9555 - val_accuracy: 0.2789 Epoch 4/30 263/263 [==============================] - 3s 12ms/step - loss: 1.6221 - accuracy: 0.4240 - val_loss: 1.5954 - val_accuracy: 0.4607 Epoch 5/30 263/263 [==============================] - 3s 12ms/step - loss: 1.3656 - accuracy: 0.5424 - val_loss: 1.2720 - val_accuracy: 0.5899 Epoch 6/30 263/263 [==============================] - 4s 17ms/step - loss: 1.1958 - accuracy: 0.6150 - val_loss: 1.1094 - val_accuracy: 0.6462 Epoch 7/30 263/263 [==============================] - 4s 14ms/step - loss: 1.1250 - accuracy: 0.6400 - val_loss: 1.0664 - val_accuracy: 0.6543 Epoch 8/30 263/263 [==============================] - 3s 12ms/step - loss: 1.0609 - accuracy: 0.6599 - val_loss: 1.0290 - val_accuracy: 0.6744 Epoch 9/30 263/263 [==============================] - 3s 12ms/step - loss: 1.0168 - accuracy: 0.6772 - val_loss: 0.9769 - val_accuracy: 0.6899 Epoch 10/30 263/263 [==============================] - 5s 17ms/step - loss: 0.9841 - accuracy: 0.6875 - val_loss: 0.9503 - val_accuracy: 0.7006 Epoch 11/30 263/263 [==============================] - 3s 13ms/step - loss: 0.9636 - accuracy: 0.6936 - val_loss: 0.9347 - val_accuracy: 0.7062 Epoch 12/30 263/263 [==============================] - 3s 12ms/step - loss: 0.9301 - accuracy: 0.7054 - val_loss: 0.9375 - val_accuracy: 0.7033 Epoch 13/30 263/263 [==============================] - 3s 12ms/step - loss: 0.9034 - accuracy: 0.7145 - val_loss: 0.9450 - val_accuracy: 0.6981 Epoch 14/30 263/263 [==============================] - 5s 19ms/step - loss: 0.8967 - accuracy: 0.7169 - val_loss: 0.8675 - val_accuracy: 0.7287 Epoch 15/30 263/263 [==============================] - 3s 13ms/step - loss: 0.8766 - accuracy: 0.7224 - val_loss: 0.8910 - val_accuracy: 0.7164 Epoch 16/30 263/263 [==============================] - 3s 12ms/step - loss: 0.8658 - accuracy: 0.7253 - val_loss: 0.8921 - val_accuracy: 0.7094 Epoch 17/30 263/263 [==============================] - 3s 12ms/step - loss: 0.8518 - accuracy: 0.7298 - val_loss: 0.8501 - val_accuracy: 0.7351 Epoch 18/30 263/263 [==============================] - 5s 18ms/step - loss: 0.8406 - accuracy: 0.7337 - val_loss: 0.8205 - val_accuracy: 0.7425 Epoch 19/30 263/263 [==============================] - 3s 13ms/step - loss: 0.8258 - accuracy: 0.7385 - val_loss: 0.8407 - val_accuracy: 0.7329 Epoch 20/30 263/263 [==============================] - 3s 12ms/step - loss: 0.8200 - accuracy: 0.7383 - val_loss: 0.8093 - val_accuracy: 0.7513 Epoch 21/30 263/263 [==============================] - 3s 12ms/step - loss: 0.8161 - accuracy: 0.7402 - val_loss: 0.8469 - val_accuracy: 0.7436 Epoch 22/30 263/263 [==============================] - 5s 20ms/step - loss: 0.8058 - accuracy: 0.7432 - val_loss: 0.8235 - val_accuracy: 0.7415 Epoch 23/30 263/263 [==============================] - 3s 12ms/step - loss: 0.8007 - accuracy: 0.7436 - val_loss: 0.8027 - val_accuracy: 0.7533 Epoch 24/30 263/263 [==============================] - 3s 13ms/step - loss: 0.7920 - accuracy: 0.7472 - val_loss: 0.7534 - val_accuracy: 0.7664 Epoch 25/30 263/263 [==============================] - 3s 12ms/step - loss: 0.7714 - accuracy: 0.7532 - val_loss: 0.7814 - val_accuracy: 0.7542 Epoch 26/30 263/263 [==============================] - 5s 19ms/step - loss: 0.7757 - accuracy: 0.7538 - val_loss: 0.7556 - val_accuracy: 0.7594 Epoch 27/30 263/263 [==============================] - 3s 12ms/step - loss: 0.7541 - accuracy: 0.7613 - val_loss: 0.8314 - val_accuracy: 0.7412 Epoch 28/30 263/263 [==============================] - 3s 12ms/step - loss: 0.7613 - accuracy: 0.7589 - val_loss: 0.7555 - val_accuracy: 0.7686 Epoch 29/30 263/263 [==============================] - 4s 14ms/step - loss: 0.7594 - accuracy: 0.7593 - val_loss: 0.7642 - val_accuracy: 0.7637 Epoch 30/30 263/263 [==============================] - 5s 17ms/step - loss: 0.7430 - accuracy: 0.7625 - val_loss: 0.7616 - val_accuracy: 0.7629
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()

Sequential Model_2, had a fast learing rate for the first 6 epochs, then slowed at epoch 14 and never made that much more progress only gaining another 2 percent in accuracy from the halfway point of training to the end. Inspite of adding more dense layer.
# Get predictions for the test data
y_pred = model_2.predict(X_test)
# Print classification report
from sklearn.metrics import classification_report
print(classification_report(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)))
# Print confusion matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)))
# Final observations
# The second model performed better than the first model, achieving an accuracy of 80%. However, the model still struggles to correctly classify certain digits, such as 3 and 8. Further improvements could be made by experimenting with different hyperparameters, such as the number of layers, the number of neurons in each layer, and the learning rate.
563/563 [==============================] - 2s 3ms/step
precision recall f1-score support
0 0.84 0.75 0.79 1814
1 0.74 0.79 0.77 1828
2 0.77 0.80 0.79 1803
3 0.62 0.77 0.69 1719
4 0.79 0.83 0.81 1812
5 0.76 0.68 0.72 1768
6 0.80 0.74 0.77 1832
7 0.83 0.77 0.80 1808
8 0.72 0.72 0.72 1812
9 0.75 0.74 0.75 1804
accuracy 0.76 18000
macro avg 0.76 0.76 0.76 18000
weighted avg 0.76 0.76 0.76 18000
[[1363 79 26 54 41 11 57 24 62 97]
[ 21 1451 32 85 88 16 22 53 33 27]
[ 10 35 1447 101 34 24 7 77 27 41]
[ 17 55 70 1323 28 92 14 43 49 28]
[ 19 69 35 44 1501 28 44 9 25 38]
[ 24 43 19 226 26 1198 75 17 84 56]
[ 71 42 19 32 76 80 1357 12 120 23]
[ 10 81 139 85 15 18 19 1388 18 35]
[ 37 54 50 70 56 45 87 15 1309 89]
[ 44 51 31 107 33 71 16 35 80 1336]]
test_pred = model_2.predict(X_test)
test_pred = np.argmax(test_pred, axis=1)
print(X_test, (test_pred))
563/563 [==============================] - 2s 3ms/step [[0.15905097 0.18349686 0.19206432 ... 0.43143883 0.4360851 0.44780627] [0.45161137 0.44769022 0.44376904 ... 0.1652502 0.18922432 0.20883021] [0.52256864 0.52834475 0.53456783 ... 0.50266707 0.5012169 0.5027937 ] ... [0.6517247 0.64594865 0.6385533 ... 0.6388313 0.6383843 0.63793725] [0.5395208 0.5360466 0.5286514 ... 0.56779647 0.5599541 0.55603296] [0.11836078 0.11836078 0.11836078 ... 0.13760431 0.1359851 0.13368313]] [2 7 2 ... 7 9 2]
Note: Earlier, we noticed that each entry of the target variable is a one-hot encoded vector but to print the classification report and confusion matrix, we must convert each entry of y_test to a single label.
y_test = np.argmax(y_test, axis = -1)
# Import required library tools
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# classification report
print(classification_report(y_test, test_pred))
cm = confusion_matrix(y_test, test_pred)
plt.figure(figsize = (8, 5))
sns.heatmap(cm, annot = True, fmt = '.0f')
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.show()
precision recall f1-score support
0 0.84 0.75 0.79 1814
1 0.74 0.79 0.77 1828
2 0.77 0.80 0.79 1803
3 0.62 0.77 0.69 1719
4 0.79 0.83 0.81 1812
5 0.76 0.68 0.72 1768
6 0.80 0.74 0.77 1832
7 0.83 0.77 0.80 1808
8 0.72 0.72 0.72 1812
9 0.75 0.74 0.75 1804
accuracy 0.76 18000
macro avg 0.76 0.76 0.76 18000
weighted avg 0.76 0.76 0.76 18000

Final Observations: The ANN model_2, is performing well in terms of the model does not seem to be overfitting the training data. However the accuracy for the model
import h5py
with h5py.File('/content/drive/My Drive/ElectiveProjects/svhn.h5', 'r') as hf:
X_train = hf['X_train'][:]
y_train = hf['y_train'][:]
X_test = hf['X_test'][:]
y_test = hf['y_test'][:]
hf.close()
Check the number of images in the training and the testing dataset.
len(X_train), len(X_test)
(42000, 18000)
Observation:
There are 42,000 images in the training data and 18,000 images in the test dataset as expected.
print('Shape:', X_train[0].shape)
print()
print("First:\n", X_train[0])
Shape: (32, 32) First: [[ 33.0704 30.2601 26.852 ... 71.4471 58.2204 42.9939] [ 25.2283 25.5533 29.9765 ... 113.0209 103.3639 84.2949] [ 26.2775 22.6137 40.4763 ... 113.3028 121.775 115.4228] ... [ 28.5502 36.212 45.0801 ... 24.1359 25.0927 26.0603] [ 38.4352 26.4733 23.2717 ... 28.1094 29.4683 30.0661] [ 50.2984 26.0773 24.0389 ... 49.6682 50.853 53.0377]]
Reshape the dataset to be able to pass them to CNNs. Remember that we always have to give a 4D array as input to CNNs
X_train = X_train.reshape(X_train.shape[0], 32, 32, 1)
X_test = X_test.reshape(X_test.shape[0], 32, 32, 1)
Normalize inputs from 0-255 to 0-1
X_train = X_train / 255.0
X_test = X_test / 255.0
Print New shape of Training and Test
print('Training set:', X_train.shape, y_train.shape)
print('Test set:', X_test.shape, y_test.shape)
Training set: (42000, 32, 32, 1) (42000,) Test set: (18000, 32, 32, 1) (18000,)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
y_train
y_test
array([[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 1., ..., 0., 0., 0.]], dtype=float32)
Observation:
Now that we have done data preprocessing, let's build a CNN model. Fix the seed for random number generators
np.random.seed(42)
import random
random.seed(42)
tf.random.set_seed(42)
def cnn_model_1():
cnn_model_1 = Sequential()
cnn_model_1.add(Conv2D(filters = 16, kernel_size = (3, 3), padding = "same", input_shape = (32,32,1)))
cnn_model_1.add(LeakyReLU(0.1))
cnn_model_1.add(Conv2D(filters = 32, kernel_size = (3, 3), padding = "same"))
cnn_model_1.add(LeakyReLU(0.1))
cnn_model_1.add(MaxPooling2D(pool_size = (2, 2)))
cnn_model_1.add(Flatten())
cnn_model_1.add(Dense(32))
cnn_model_1.add(LeakyReLU(0.1))
cnn_model_1.add(Dense(10, activation = 'softmax'))
cnn_model_1.compile(loss='categorical_crossentropy', optimizer = Adam(learning_rate = 0.001), metrics=['accuracy'])
return cnn_model_1
cnn_model_1 = cnn_model_1()
cnn_model_1.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 32, 32, 16) 160
leaky_re_lu_5 (LeakyReLU) (None, 32, 32, 16) 0
conv2d_5 (Conv2D) (None, 32, 32, 32) 4640
leaky_re_lu_6 (LeakyReLU) (None, 32, 32, 32) 0
max_pooling2d_2 (MaxPooling (None, 16, 16, 32) 0
2D)
flatten_1 (Flatten) (None, 8192) 0
dense_11 (Dense) (None, 32) 262176
leaky_re_lu_7 (LeakyReLU) (None, 32) 0
dense_12 (Dense) (None, 10) 330
=================================================================
Total params: 267,306
Trainable params: 267,306
Non-trainable params: 0
_________________________________________________________________
history_cnn_model_1 = cnn_model_1.fit(X_train, y_train, validation_split=0.2, batch_size=32, verbose=1, epochs=20)
Epoch 1/20 1050/1050 [==============================] - 96s 90ms/step - loss: 1.1274 - accuracy: 0.6303 - val_loss: 0.6497 - val_accuracy: 0.8087 Epoch 2/20 1050/1050 [==============================] - 90s 86ms/step - loss: 0.5352 - accuracy: 0.8475 - val_loss: 0.5254 - val_accuracy: 0.8448 Epoch 3/20 1050/1050 [==============================] - 91s 86ms/step - loss: 0.4416 - accuracy: 0.8700 - val_loss: 0.5049 - val_accuracy: 0.8532 Epoch 4/20 1050/1050 [==============================] - 94s 90ms/step - loss: 0.3781 - accuracy: 0.8888 - val_loss: 0.4486 - val_accuracy: 0.8739 Epoch 5/20 1050/1050 [==============================] - 91s 86ms/step - loss: 0.3330 - accuracy: 0.9004 - val_loss: 0.4592 - val_accuracy: 0.8717 Epoch 6/20 1050/1050 [==============================] - 90s 85ms/step - loss: 0.2944 - accuracy: 0.9115 - val_loss: 0.4640 - val_accuracy: 0.8735 Epoch 7/20 1050/1050 [==============================] - 87s 83ms/step - loss: 0.2622 - accuracy: 0.9216 - val_loss: 0.4506 - val_accuracy: 0.8807 Epoch 8/20 1050/1050 [==============================] - 90s 86ms/step - loss: 0.2332 - accuracy: 0.9279 - val_loss: 0.4920 - val_accuracy: 0.8681 Epoch 9/20 1050/1050 [==============================] - 85s 81ms/step - loss: 0.2094 - accuracy: 0.9365 - val_loss: 0.4703 - val_accuracy: 0.8782 Epoch 10/20 1050/1050 [==============================] - 86s 82ms/step - loss: 0.1873 - accuracy: 0.9424 - val_loss: 0.4922 - val_accuracy: 0.8782 Epoch 11/20 1050/1050 [==============================] - 86s 82ms/step - loss: 0.1663 - accuracy: 0.9471 - val_loss: 0.5408 - val_accuracy: 0.8752 Epoch 12/20 1050/1050 [==============================] - 85s 81ms/step - loss: 0.1521 - accuracy: 0.9519 - val_loss: 0.5748 - val_accuracy: 0.8701 Epoch 13/20 1050/1050 [==============================] - 86s 81ms/step - loss: 0.1331 - accuracy: 0.9571 - val_loss: 0.6197 - val_accuracy: 0.8671 Epoch 14/20 1050/1050 [==============================] - 95s 91ms/step - loss: 0.1233 - accuracy: 0.9601 - val_loss: 0.6305 - val_accuracy: 0.8640 Epoch 15/20 1050/1050 [==============================] - 86s 82ms/step - loss: 0.1132 - accuracy: 0.9633 - val_loss: 0.6549 - val_accuracy: 0.8707 Epoch 16/20 1050/1050 [==============================] - 86s 81ms/step - loss: 0.1008 - accuracy: 0.9669 - val_loss: 0.7015 - val_accuracy: 0.8658 Epoch 17/20 1050/1050 [==============================] - 85s 81ms/step - loss: 0.0929 - accuracy: 0.9704 - val_loss: 0.6903 - val_accuracy: 0.8750 Epoch 18/20 1050/1050 [==============================] - 86s 82ms/step - loss: 0.0798 - accuracy: 0.9749 - val_loss: 0.7664 - val_accuracy: 0.8681 Epoch 19/20 1050/1050 [==============================] - 86s 82ms/step - loss: 0.0778 - accuracy: 0.9744 - val_loss: 0.7585 - val_accuracy: 0.8714 Epoch 20/20 1050/1050 [==============================] - 90s 86ms/step - loss: 0.0742 - accuracy: 0.9756 - val_loss: 0.8155 - val_accuracy: 0.8701
# Plotting the accuracies
dict_hist = history_cnn_model_1.history
list_ep = [i for i in range(1, 21)]
plt.figure(figsize = (8, 8))
plt.plot(list_ep, dict_hist['accuracy'], ls = '--', label = 'accuracy')
plt.plot(list_ep, dict_hist['val_accuracy'], ls = '--', label = 'val_accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend()
<matplotlib.legend.Legend at 0x7a5e53fc6140>

OBSERVATIONS:*Convolutional model 1 above, is overfitting on the training data. As displayed in the plot above, the model did very well reaching a peak accuracy of 97.56%, however the the model is only coming in at 87% on the testing data. This is an indicator that this model design is now overfitting the data and will not actually generalize to data beyond the training data very well.
Let's build another model and see if we can get a better model with generalized performance.
First, we need to clear the previous model's history from the Keras backend. Also, let's fix the seed again after clearing the backend.
from tensorflow.keras import backend
backend.clear_session()
# Fixing the seed for random number generators
np.random.seed(42)
import random
random.seed(42)
tf.random.set_seed(42)
def cnn_model_2():
cnn_model_2 = Sequential()
cnn_model_2.add(Conv2D(filters = 16, kernel_size = (3, 3), padding = "same", input_shape = (32,32,1)))
cnn_model_2.add(LeakyReLU(0.1))
cnn_model_2.add(Conv2D(filters = 32, kernel_size = (3, 3), padding = "same"))
cnn_model_2.add(LeakyReLU(0.1))
cnn_model_2.add(MaxPooling2D(pool_size = (2, 2)))
cnn_model_2.add(BatchNormalization())
cnn_model_2.add(Conv2D(filters = 32, kernel_size = (3, 3), padding = "same"))
cnn_model_2.add(LeakyReLU(0.1))
cnn_model_2.add(Conv2D(filters = 64, kernel_size = (3, 3), padding = "same"))
cnn_model_2.add(LeakyReLU(0.1))
cnn_model_2.add(MaxPooling2D(pool_size = (2, 2)))
cnn_model_2.add(BatchNormalization())
cnn_model_2.add(Flatten())
cnn_model_2.add(Dense(32))
cnn_model_2.add(LeakyReLU(0.1))
cnn_model_2.add(Dropout(0.5))
cnn_model_2.add(Dense(10, activation = 'softmax'))
cnn_model_2.compile(loss='categorical_crossentropy', optimizer = Adam(learning_rate = 0.001), metrics=['accuracy'])
return cnn_model_2
cnn_model_2 = cnn_model_2()
cnn_model_1.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 32, 32, 16) 160
leaky_re_lu_5 (LeakyReLU) (None, 32, 32, 16) 0
conv2d_5 (Conv2D) (None, 32, 32, 32) 4640
leaky_re_lu_6 (LeakyReLU) (None, 32, 32, 32) 0
max_pooling2d_2 (MaxPooling (None, 16, 16, 32) 0
2D)
flatten_1 (Flatten) (None, 8192) 0
dense_11 (Dense) (None, 32) 262176
leaky_re_lu_7 (LeakyReLU) (None, 32) 0
dense_12 (Dense) (None, 10) 330
=================================================================
Total params: 267,306
Trainable params: 267,306
Non-trainable params: 0
_________________________________________________________________
history_cnn_model_2 = cnn_model_2.fit(X_train, y_train, validation_split=0.2, batch_size=32, verbose=1, epochs=30)
Epoch 1/30 1050/1050 [==============================] - 152s 142ms/step - loss: 1.1213 - accuracy: 0.6363 - val_loss: 0.5838 - val_accuracy: 0.8367 Epoch 2/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.6318 - accuracy: 0.8100 - val_loss: 0.4684 - val_accuracy: 0.8652 Epoch 3/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.5289 - accuracy: 0.8372 - val_loss: 0.4400 - val_accuracy: 0.8769 Epoch 4/30 1050/1050 [==============================] - 147s 140ms/step - loss: 0.4788 - accuracy: 0.8562 - val_loss: 0.4196 - val_accuracy: 0.8779 Epoch 5/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.4377 - accuracy: 0.8681 - val_loss: 0.4006 - val_accuracy: 0.8855 Epoch 6/30 1050/1050 [==============================] - 147s 140ms/step - loss: 0.4031 - accuracy: 0.8782 - val_loss: 0.3997 - val_accuracy: 0.8867 Epoch 7/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.3750 - accuracy: 0.8864 - val_loss: 0.3958 - val_accuracy: 0.8913 Epoch 8/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.3476 - accuracy: 0.8941 - val_loss: 0.3636 - val_accuracy: 0.9035 Epoch 9/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.3293 - accuracy: 0.8979 - val_loss: 0.3748 - val_accuracy: 0.9039 Epoch 10/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.3165 - accuracy: 0.9031 - val_loss: 0.3651 - val_accuracy: 0.9060 Epoch 11/30 1050/1050 [==============================] - 148s 141ms/step - loss: 0.2904 - accuracy: 0.9096 - val_loss: 0.4153 - val_accuracy: 0.8901 Epoch 12/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.2805 - accuracy: 0.9126 - val_loss: 0.3508 - val_accuracy: 0.9127 Epoch 13/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.2636 - accuracy: 0.9168 - val_loss: 0.3937 - val_accuracy: 0.8944 Epoch 14/30 1050/1050 [==============================] - 148s 141ms/step - loss: 0.2557 - accuracy: 0.9186 - val_loss: 0.3652 - val_accuracy: 0.9102 Epoch 15/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.2420 - accuracy: 0.9241 - val_loss: 0.3614 - val_accuracy: 0.9135 Epoch 16/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.2368 - accuracy: 0.9248 - val_loss: 0.3685 - val_accuracy: 0.9151 Epoch 17/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.2230 - accuracy: 0.9284 - val_loss: 0.5917 - val_accuracy: 0.8852 Epoch 18/30 1050/1050 [==============================] - 147s 140ms/step - loss: 0.2194 - accuracy: 0.9295 - val_loss: 0.4182 - val_accuracy: 0.9063 Epoch 19/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.2087 - accuracy: 0.9319 - val_loss: 0.3831 - val_accuracy: 0.9126 Epoch 20/30 1050/1050 [==============================] - 148s 141ms/step - loss: 0.1973 - accuracy: 0.9362 - val_loss: 0.4564 - val_accuracy: 0.9090 Epoch 21/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.1924 - accuracy: 0.9361 - val_loss: 0.3986 - val_accuracy: 0.9054 Epoch 22/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.1890 - accuracy: 0.9380 - val_loss: 0.4425 - val_accuracy: 0.8961 Epoch 23/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.1771 - accuracy: 0.9414 - val_loss: 0.4040 - val_accuracy: 0.9189 Epoch 24/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.1826 - accuracy: 0.9394 - val_loss: 0.4478 - val_accuracy: 0.9081 Epoch 25/30 1050/1050 [==============================] - 149s 142ms/step - loss: 0.1692 - accuracy: 0.9427 - val_loss: 0.4481 - val_accuracy: 0.9092 Epoch 26/30 1050/1050 [==============================] - 148s 141ms/step - loss: 0.1727 - accuracy: 0.9419 - val_loss: 0.4320 - val_accuracy: 0.9149 Epoch 27/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.1647 - accuracy: 0.9462 - val_loss: 0.4541 - val_accuracy: 0.9155 Epoch 28/30 1050/1050 [==============================] - 151s 144ms/step - loss: 0.1592 - accuracy: 0.9472 - val_loss: 0.4283 - val_accuracy: 0.9136 Epoch 29/30 1050/1050 [==============================] - 147s 140ms/step - loss: 0.1536 - accuracy: 0.9490 - val_loss: 0.4689 - val_accuracy: 0.9057 Epoch 30/30 1050/1050 [==============================] - 150s 143ms/step - loss: 0.1526 - accuracy: 0.9499 - val_loss: 0.4785 - val_accuracy: 0.8989
# Plotting the accuracies
dict_hist = history_cnn_model_2.history
list_ep = [i for i in range(1, 31)]
plt.figure(figsize = (8, 8))
plt.plot(list_ep, dict_hist['accuracy'], ls = '--', label = 'accuracy')
plt.plot(list_ep, dict_hist['val_accuracy'], ls = '--', label = 'val_accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend()
plt.savefig('')
plt.show()

Observations:__
# Make prediction on the test data using model_2
test_pred = cnn_model_2.predict(X_test)
test_pred = np.argmax(test_pred, axis = -1)
563/563 [==============================] - 22s 38ms/step
Note: Earlier, we noticed that each entry of the target variable is a one-hot encoded vector, but to print the classification report and confusion matrix, we must convert each entry of y_test to a single label.
y_test = np.argmax(y_test, axis = -1)
# Importing required functions
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# Printing the classification report
print(classification_report(y_test, test_pred))
# Plotting the heatmap using confusion matrix
cm = confusion_matrix(y_test, test_pred)
plt.figure(figsize = (8, 5))
sns.heatmap(cm, annot = True, fmt = '.0f')
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.show()
precision recall f1-score support
0 0.90 0.94 0.92 1814
1 0.95 0.84 0.89 1828
2 0.91 0.92 0.91 1803
3 0.87 0.88 0.88 1719
4 0.90 0.92 0.91 1812
5 0.89 0.91 0.90 1768
6 0.87 0.90 0.89 1832
7 0.90 0.93 0.92 1808
8 0.92 0.87 0.89 1812
9 0.91 0.90 0.90 1804
accuracy 0.90 18000
macro avg 0.90 0.90 0.90 18000
weighted avg 0.90 0.90 0.90 18000

Final Observations: The Convolutional Neural Network (CNN) framework significantly outperformed the traditional Artificial Neural Network (ANN) in terms of accuracy for both training and validation datasets. The confusion matrix for the CNN model indicates that it was able to identify the numbers with higher confidence accurately.
However, the model's training could have been halted at epoch 19, at which point the training accuracy was at (93%), and the validation accuracy was at (91%)the closest the two measures came during the 30 epochs. After the 19th epoch, the performance diverged, with the validation accuracy declining to about (88%).
A solution to this for future projects could be using early stopping.
Analysis of CNN and ANN Performance: In the evaluation of model performances for the image classification task between the Convolutional Neural Network (CNN) and the Artificial Neural Network (ANN) Precision, Recall, and F1-Score Analysis The CNN model demonstrates superior precision across all classes, indicating a higher accuracy in its predictions compared to the ANN. The precision for class 0 is higher in the **CNN (0.90) than in the ANN (0.84). Similarly, the CNN outperforms the ANN in recall rates, showcasing its enhanced ability to identify all relevant instances within the dataset. The f1-scores further highlight the CNN**'s balanced precision and recall, illustrating its superior performance in correctly classifying images across all categories.
Overall Accuracy The overall accuracy metric starkly differentiates the two models, with the CNN achieving an impressive 90% accuracy rate, substantially higher than the ANN's 76%. This metric clearly illustrates the CNN's superior capability in managing the complexities inherent in the dataset, affirming its effectiveness in image classification tasks.
Implications for Future Work The analysis underscores the CNN's advantage in processing image data, attributed to its ability to capture spatial hierarchies and relationships. Given the significant performance gap between the CNN and ANN, future projects involving image classification are recommended to leverage the architectural strengths of CNNs. This will ensure higher accuracy and efficiency in model outcomes.
# prompt: using nbconvert convert the notebook to html
!jupyter nbconvert --to html '/content/RobertSloanElective_digit_recognition.ipynb'
[NbConvertApp] Converting notebook /content/RobertSloanElective_digit_recognition.ipynb to html [NbConvertApp] Writing 1292955 bytes to /content/RobertSloanElective_digit_recognition.html
cnn_model_2.save('/mnt/data/digit_recognition_model.h5') # Save the model for use
cnn_model_2.save('/content/drive/My Drive/digit_recognition_model.h5') # Save the model to Google Drive